Chap01. 03 다양한 인덱스 스캔 방식
인덱스 스캔 방식은 크게 아래와 같습니다.
1) Index Range Scan
2) Index Full Scan
3) Index Unique Scan
4) Index Skip Scan
5) Index Fast Full Scan
6) Index Range Scan Decending
7) Index Combine
8) Inlist Iterator
01. Index Range Scan

Index Range Scan은
- Index의 Root Block부터 Leaf Block까지 수직적 탐색 후 Leaf Block의 필요한 범위만 Scan하는 방식입니다.
- B*Tree 인덱스의 가장 일반적이고 정상적인 형태의 액세스 방식입니다.
- Index Range Scan 과정을 거쳐 생성된 결과 집합은 인덱스 컬럼순으로 정렬된 상태이기에 sort order by 연산을 생략하거나 min/max 값을 빠르게 추출할 수 있습니다.
특징
- 항상 빠른 속도를 보장하지 않는다.
- 인덱스 스캔하는 범위를 얼마나 줄일 수 있느냐?
- 테이블로 액세스 하는 횟수를 얼마큼 줄일 수 있느냐?
- SQL 튜닝의 핵심 원리
- Index를 구성하는 선두 컬럼을 조건절에 사용
EMP Table에 DEPTNO컬럼 기준으로 EMP_X01이라는 Index가 생성되어있습니다.
SELECT DEPTNO, EMPNO, ENAME, SAL
FROM EMP
WHERE DEPTNO = 10
AND SAL >= 2000;
실행계획에 Index Range Scan이 나타나려면
- Index를 구성하는 선두컬럼이 WHERE 조건절에 사용되어야 합니다.
- EMP_X01의 DEPTNO가 선두컬럼으로 생성되어있고
- WHERE 조건절에 DEPTNO가 사용되어 Index Range Scan 사용
- Index Range Scan을 사용한다하여 항상 빠르지는 않습니다. 관건은
- Leaf Block의 Scan양(수평적탐색)을 얼마큼 줄일 수 있느냐?
- 그 후 Table로 Access 하는 횟수를 얼마큼 줄일 수 있느냐?
[Leaf Block의 Scan양에 따라 성능 차이가 존재]
[그림1]

[Table Access 하는 횟수에 따른 성능 차이가 존재]
[그림2]

[그림2] 에서 하단의 사각형은 Index Scan 후 Table Access가 발생하는 현상을 그림으로 표현한 것입니다.
Table Full Scan 부터 알아보겠습니다.
Table Full Scan
Table을 첫행부터 끝행까지 전체 읽는 것을 말합니다.
WHERE조건절로 구성된 컬럼의 Index가 존재하지 않는 상황에서 Query 수행 시 대게 Table Full Scan이 일어납니다.
아래 Query를 실행할 때 Table Full Scan을 어떻게 하는지 봅시다.
SELECT DEPTNO, EMPNO, ENAME, MGR, SAL
FROM EMP
WHERE ENAME LIKE '%E%';

EMP Table에서 WHERE 조건의 ENAME LIKE '%E%' 만족하는 레코드를
맨위에서부터 맨 아래까지 순서대로 확인하면서 결과를 하나씩 하나씩 쌓여 결과를 보여주게 됩니다.
실행계획 확인 시 TABLE ACCESS FULL이 생긴 것을 확인할 수 있습니다.

본론으로 돌어와 Table Access를 확인해보겠습니다.
Table Access
[그림2] 에서 Table Access의 정확한 의미는 Index를 통해 Scan한 후 Table을 방문할 때를 말합니다.
예시 Query
SELECT DEPTNO, EMPNO, ENAME, SAL
FROM EMP
WHERE DEPTNO = 10
AND SAL >= 2000;우리는 EMP_X01 Index 가 존재하는것을 알고 있는데요.
[그림2] 도형을 왼쪽으로 45도 돌려보도록 하겠습니다.
삼각형은 우리가 알고있던 Index 구조이며 사각형은 Table 레코드라 보시면 됩니다.

Table을 찾아가는 이유는 우리는 Query상 DATA 중 deptno는 Index를 통해 값을 알 수 있지만
조회하는 DATA(EMPNO, ENAME, SAL)와 WHERE의 조건 DATA를 모르기에 Disk나 Memory에서 가져와야 하는데요.
※ Index의 Rowid를 통해 Table Record를 순차적으로 탐색하지 않고 Direct로 찾아갑니다.
(첫장에서 이야기하였던 Index가 목차랑 비슷하는 이유가 이것 때문입니다.)
※ Table Access 발생량이 많을 수록 Single Block I/O 발생량이 많아 질수 있기에
성능에 영향을 미치게 됩니다.

위 Query의 실행계획을 보도록할까요?
Index를 사용한 부분은 Index Range Scan이 나타나며
Index에 의한 Table 접근을 Table Access By Index Rowid로 표기되었습니다.
Predicate Information영역을 보게되면
ID 2 -> Index 사용 시 Scan되는 접근(Access) 구간이 "DEPTNO = 10" 임과
ID 1 -> Table Access 시 "SAL >= 2000" 조건으로 데이터가 걸러짐(Filter)을 알 수 있습니다.
02. Index Full Scan

Index Full Scan은
Index Leaf Block을 전체 수평적탐색 하는 방식이며, (수직적탐색X)
대다수 데이터 검색을 위한 최적의 인덱스가 없을 때 차선으로 선택됩니다.
특징
- 보편 -> 옵티마이저는 Index가 없을 경우 Table Full Scan을 고려(적당한 인덱스가 없을 경우 Table Full Scan 수행)
- 조회 조건의 Index가 있으나, 선두 컬럼이 아니지만
- 옵티마이저가 인덱스 활용 시 이익이 있다고 판단할 경우, Index Full Scan 활용
- 최종 결과 값이 적을 때 Table Full Scan 보다 Index Full Scan이 효율적, 최종 결과 값이 많을 때는 Table Full Scan이 효율적
- 이유 : Index 스캔하는 범위가 Table Full Scan하는 양만큼 존재한다면 Index의 수평적 탐색 과정 후 Table Random Access 하는 양이 많을 수도 있어 부담되기 때문입니다.
EMP Table에 [DEPTNO, SAL]컬럼 기준으로 EMP_X02이라는 결합 Index가 생성되어있습니다.
SELECT /*+ INDEX(EMP EMP_X02) */
DEPTNO, EMPNO, ENAME, SAL
FROM EMP
WHERE SAL >= 1000;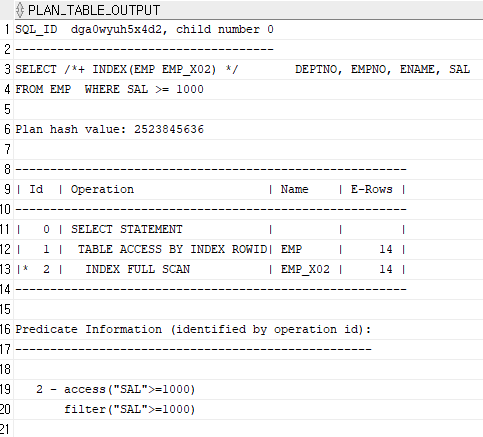
03. Index Unique Scan

Index Unique Scan은 수직적 탐색만으로 데이터를 찾는 스캔 방식입니다.
Index를 통해 '=' 조건으로만 탐색하는 경우에 작동합니다.
SELECT *
FROM EMP
WHERE EMPNO = 7788;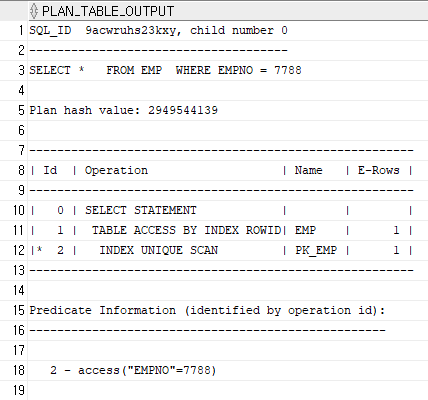
- Unique 인덱스이여도 범위검색 조건(between, 부등호, like) 검색 시 Index Range Scan으로 처리됩니다.
- Unique 결합 Index 일 경우에는 일부 컬럼만으로 검색할 때에는 Index Range Scan이 나타난다.
- jumun_x01 Index 구성 : [주문일자 + 고객ID + 상품ID] 일 때 주문일자 + 고객ID로만 검색 할 경우
04. Index Skip Scan

특징
- 조건절에 Index 선두 컬럼이 사용되지 않으며,
- Index 선두 컬럼의 Distinct Value 개수가 적고 후행 컬럼의 Distinct Value 개수가 많을 때 효과적입니다.
- Index 선두 컬럼이 Between, Like, 부등호 일 때도 사용 가능합니다.
- Skip해 나갈 때 Branch Block을 방문해 다음에 찾아갈 Leaf의 주소 정보를 얻는다.
Index Skip Scan예
CREATE TABLE EMPL (
GENDER VARCHAR2(2),
SAL NUMBER
);
INSERT INTO EMPL
SELECT 'M' AS GENDER, TO_NUMBER(LPAD(ROUND(DBMS_RANDOM.VALUE(1, 10000)), 5, '0')) AS SAL
FROM DUAL
CONNECT BY LEVEL <= 10000;
INSERT INTO EMPL
SELECT 'F' AS GENDER, TO_NUMBER(LPAD(ROUND(DBMS_RANDOM.VALUE(1, 10000)), 5, '0')) AS SAL
FROM DUAL
CONNECT BY LEVEL <= 10000;
COMMIT;
CREATE INDEX EMPL_X01 ON EMPL(GENDER, SAL);
-- Query
SELECT /*+ INDEX_SS(EMPL EMPL_X01) */
GENDER, SAL
FROM EMPL
WHERE SAL BETWEEN 2000 AND 6000;
Distinct Value가 낮은 성별 컬럼을 선두로하며
Distinct Value가 높은 연봉 컬럼을 후행으로 두었습니다.

위 그림과 테스트하는 데이터 상의 수치는 서로 다르지만 그림처럼 조건에 만족하는 부분을 읽고
아닌 부분은 다시 Branch Block으로 올라간 후 다음 조건에 만족하는 Leaf Block의 주소를 얻어
찾아가게 됩니다.
※ Skip Scan의 장점은 Index를 다시 찾아 갈 때 Root Block 부터 다시 시작하지 않고
Branch Block에서 다시 Leaf Block을 찾아간다는 점 입니다.
이 Branch Block을 다시 찾아 갈수 있는 이유는 Buffer Pinning 기법이 활용 되기 때문입니다.
04-01 In-List Iterator
특징
- Query 상 WHERE절에 IN절이 포함된 것을 말합니다.
- IN절이 '=' 조건으로 Query가 변형되면서 In절의 유형 갯수만큼 Union All로 변형됩니다.
- 조건절 In-List에 제공된 값의 종류만큼 인덱스 탐색을 반복 수행함을 뜻합니다.
- In-List로 제공하는 값의 종류가 적어야 효과가 좋다.
SQL> SELECT *
FROM 사원
WHERE 연봉 BETWEEN 2000 AND 4000
AND 성별 IN ('남', '여')
Execution Plan
---------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 INLIST ITERATOR
2 1 TABLE ACCESS (BY INDEX ROWID) OF '사원' (TABLE)
3 2 INDEX (RANGE SCAN) OF '사원_IDX' (INDEX)
05. Index Fast Full Scan
특징
- Index Fast Full Scan은 Index Full Scan보다 빠른 것을 말합니다.
- 전체 Index를 Full Scan
- 빠른 이유는 Index Tree 구조를 무시하고 Index Segment 전체를 Multiblock Read 방식으로 스캔하기 때문입니다.
- Multi block I/O는 (Disk -> Memory) 보낼 때 하나의 "Extends" 를 넘길 수 없습니다. -> Extends를 꽉채워 Memory에서 사용하기에 Single Block I/O(Index Full Scan) 보다 빠릅니다.
- Parameter db_file_multiblock_read_count(Multiblock 때 읽을 Block 개수) 수 만큼 한번에 Block을 Read 합니다.
- Index의 물리적인 순서대로 Read하기 때문에 결과 순서를 보장하지 않습니다.
일반적인 Index Full Scan은

Index의 논리적 구조를 따라 Root -> Branch1 -> 1 -> 2 -> 3 ........... -> 10 순으로 읽게 되는데요.
반면 Index Fast Full Scan은
물리적으로 디스크에 저장된 순서대로 Index Block을 읽는다.
1 -> 2 -> 10 -> 3 -> 9 순으로 읽고, 다음 8 -> 7 -> 4 -> 5 -> 6으로 읽습니다.

| Index Full Scan | Index Fast Full Scan | |
| 1 | 인덱스 구조를 따라 스캔 | 세그먼트 전체를 스캔 |
| 2 | 결과집합 순서 보장 | 결과집합 순서 보장 안 됨 |
| 3 | Single Block I/O | Multiblock I/O |
| 4 | 병렬스캔 불가(파티션 돼 있지 않다면) | 병렬스캔 가능 |
| 5 | 인덱스에 포함되지 않은 컬럼 조회 시에도 사용 가능 | 인덱스에 포함된 컬럼으로만 조회할때 사용 가능 |
06. Index Range Scan Descending
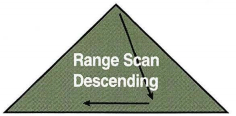
Index Range Scan을 뒤에서 읽는거라 생각하면 됩니다.
SELECT *
FROM EMP
WHERE EMPNO > 0
ORDER BY EMPNO DESC;
Execution Plan
-------------------------------------
0 SELECT STATEMEN Optimizer=ALL_ROWS
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'EMP' (TABLE)
2 1 INDEX (RANGE SCAN DESCENDING) OF 'PK_EMP' (INDEX (UNIQUE))
07. Index Combine
- Bitmap Index


- 데이터의 분포도가 좋지 않은 두 개 이상의 인덱스를 결합해 테이블 Random Access량을
줄이는데 목적이 있습니다.