01. 서브쿼리의 분류
[ Subquery ] : 하나의 SQL문에 또다른 Query Block이 존재할 때 이 Query Block을 의미함
Subquery는 SQL문의 구문 위치에 따라 명칭이 다르며 아래와 같습니다.
ⓐ Inline View : From 절에 나타나는 Subquery
ⓑ Nested Subquery : 결과집합을 한정하기 위해 where 절에 사용된 서브쿼리
ⓒ Scalar Subquery : 한 Record당 정확히 하나의 컬럼 값만을 Return하는 것이 특징
주로 Select-list에서 사용
옵티마이저는 Query Block 단위로 최적의 액세스 경로와 조인 순서, 조인 방식을
선택하는 것을 목표로 최적화를 수행합니다.
그런데 Query Block 단위로 최적화했다하여 Query 전체가 최적화됐다고 할 수는 없습니다.
마치 개개인이 좋다고하여 팀 전체가 유능하다할 수 없다는 의미와 같습니다.
02, 서브쿼리 Unnesting의 의미
Nest의 의미는 "상자 등을 차곡차곡 포개넣다" 입니다.
중첩의 의미이며,
Un의 부정의미가 붙으면서 "중첩된 상태를 풀어낸다." 뜻이 됩니다.
메인쿼리와 서브쿼리를 서로 같은 레벨로 계층구조를 풀기에 "서브쿼리 Flattening" 이라고도 한다.
[SQL]
SELECT * FROM EMP A
WHERE EXISTS (
SELECT 'X' FROM DEPT
WHERE DEPTNO = A.DEPTNO
)
AND SAL >
( SELECT AVG(SAL) FROM EMP B
WHERE EXISTS (
SELECT 'X' FROM SALGRADE
WHERE B.SAL BETWEEN LOSAL AND HISAL
AND GRADE = 4)
);

그림으로 Nested Subquery는 메인쿼리와 부모와 자식이라는
종속적인 계층적인 관계가 존재합니다.
메인 쿼리에서 읽히는 Record마다 Subquery를 반복수행하면서
조건에 맞지 않은 Data를 골라내는 것입니다.
하지만 Subquery를 처리하는 데 있어 필터 방식이 항상 최적의 수행속도를 보장하지 못하므로
옵티마이저는 아래 둘 중 하나를 선택합니다.
1) 동일한 결과를 보장하는 조인문으로 변환하고 나서 최적화한다.
-> 이를 'Subquery Unnesting'
2) Subquery를 Unnesting하지 않고 원래대로 둔 상태에서 최적화한다.
메인쿼리와 서브쿼리를 별도의 서브플랜으로 구분해 각각 최적화를 수행하며,
이때 Subquery에 필터 오퍼레이션이 나타난다.
03. 서브쿼리 Unnesting의 이점
Subquery와 메인쿼리를 같은 레벨로 풀 시 다양한 액세스 경로와
Join 메소드를 평가할 수있다.
옵티마이저는 많은 조인테크닉을 가지기 때문에 조인 형태로 변환했을 때
더 나은 실행계획을 찾을 가능성이 높아진다.
Subquery Unnesting 관련 Hint
[ UNNEST ] : Subquery를 Unnesting 함으로써 Join 방식으로 최적화하도록 유도한다.
[ NO_UNNEST ] : Subquery를 그대로 둔 상태에서 Filter 방식으로 최적화하도록 유도한다.
04. 서브쿼리 Unnesting 기본 예시
[SQL]
SELECT * FROM EMP
WHERE DEPTNO IN (SELECT /*+ NO_UNNEST */ DEPTNO FROM DEPT);

Subquery를 그대로 두며 Filter 방식으로 최적화한 실행계획 모습입니다.
17Line의 Predecate 정보에서
3 - ACCESS("DEPTNO"=:B1)
Bind 변수로 처리된 부분이 보이는데 사용자가 Query 상에 저런 조건을 작성하지 않았음에도
옵티마이저가 Subquery를 별도의 서브플랜으로 최적화 한다는 점을 알 수 있습니다.
※ Unnesting 하지 않은 Query는 메인 쿼리에서 읽히는 Record마다 값을 넘기면서
Subquery를 반복 수행한다.
/*+ UNNEST */ Hint 사용하거나
옵티마이저가 스스로 Unnesting을 선택한다면
Query는 아래와 같은 조인문 형태가 됩니다.
[SQL]
SELECT *
FROM (SELECT DEPTNO FROM DEPT) A, EMP B
WHERE B.DEPTNO = A.DEPTNO;
뷰 Merging 과정을 거쳐 최종적으로 아래와 같은 형태가 됩니다.
[SQL]
SELECT EMP.* FROM DEPT, EMP
WHERE EMP.DEPTNO = DEPT.DEPTNO;
05. Unnesting 된 쿼리의 조인 순서 조정
※ Unnesting에 의해 일반 Join문으로 변환된 후에는 EMP, DEPT 어느쪽이든
Driving Table로 선택될 수 있다.
Unnesting된 Query의 Join 순서를 조정하는 방법에 대해 살펴보겠습니다.
메인 쿼리 집합을 먼저 Driving 해보자
[SQL]
SELECT /*+ LEADING(EMP) */ * FROM EMP
WHERE DEPTNO IN (SELECT /*+ UNNEST */ DEPTNO FROM DEPT);
=> 11g에서 Test할 시 실행계획에 EMP Table과 Index만 계획상에 나타나는데
DEPT Table의 정보없이 EMP Table만 으로도 충분하기에 옵티마이저가
그런 결과를 내었다. 나중에 뒷장에서 이에 대한 내용 나옵니다.
(불필요한 조인으로 쿼리 변환)
=> Leading Hint으로 메인쿼리 집합을 먼저 Driving 하는 것은 쉽습니다.
Subquery 집합을 먼저 Driving 해보자
[SQL]
SELECT /*+ LEADING(DEPT) */ * FROM EMP
WHERE DEPTNO IN (SELECT /*+ UNNEST */ DEPTNO FROM DEPT);
Subquery에서는 메인 쿼리에 있는 Table을 참조할 수 있지만
메인 쿼리에서 Subquery 쪽 Table을 참조하지는 못하기에
LEADING(DEPT) Hint 사용 방식은 불가능하다.
[SQL]
SELECT /*+ ORDERED */ * FROM EMP
WHERE DEPTNO IN (SELECT /*+ UNNEST */ DEPTNO FROM DEPT);
=> Leading Hint 대신 Ordered Hint 사용
10g부터 사용가능한 QB_NAME Hint
[SQL]
SELECT /*+ LEADING(DEPT@QB1) */ * FROM EMP
WHERE DEPTNO IN (SELECT /*+ UNNEST QB_NAME(QB1) */ DEPTNO FROM DEPT);
[ QB_NAME ] : 사용자가 Subquery의 명명을 직접 지어주는 것을 의미하며
Main Query에서 해당 명명을 이용하여 지시를 하기 위해서 입니다.
06. 서브쿼리가 M쪽 집합이거나 Nonunique 인덱스 일 때
여태까지 Test한 메인 쿼리의 EMP, 서브쿼리의 DEPT Table이
M:1 관계이기에 일반 조인문으로 바꾸더라도 Query 결과가 보장되었습니다.
옵티마이저가 DEPT Table의 PK제약이 설정된 것을 통해 DEPT Table이 1쪽 집합
이라는 사실을 알 수 있기 때문입니다.
만약 Subquery 쪽 Table이 Join 컬럼에 PK/Unique 제약 또는 Unique Index가 없다면,
일반 조인문처럼 처리했을 때 어떻게 될까요?
<사례1>
[SQL]
SELECT * FROM DEPT
WHERE DEPTNO IN (SELECT DEPTNO FROM EMP);
=> DEPT Table 기준으로 EMP Table을 필터링하는 형태
=> DEPT Table이 기준 집합이므로 결과집합은 DEPT Table의 총 건수를 넘지 않아야 한다.
만약 옵티마이저가 아래와 같은 일반 조인문으로 변경시
M쪽 집합인 EMP Table 단위의 결과집합이 만들어지므로 결과내용에 오류가 생깁니다.
[SQL]
SELECT *
FROM (SELECT DEPTNO FROM EMP) A, DEPT B
WHERE B.DEPTNO = A.DEPTNO;
<사례2>
[SQL]
SELECT * FROM EMP
WHERE DEPTNO IN (SELECT DEPTNO FROM DEPT);
M쪽 집합을 Driving해 1쪽 집합을 Subquery로 필터링하도록 작성되었고
Join문으로 바꾸더라도 결과에 오류가 생기지는 않습니다.
하지만 DEPT Table에 PK/Unique제약 또는 Unique Index가 없다면
옵티마이저는 EMP와 DEPT간의 관계를 알수 없고, 결과를 확신할 수 없으니
일반 Join문으로의 Query 변환을 시도하지 않습니다.
이때 옵티마이저는 두 가지 방식 중 하나를 선택하는데, Unnesting 후
어느 쪽 집합이 먼저 Driving 되느냐에 따라 달라집니다.
1) 1쪽 집합임을 확신할 수 없는 Subquery 쪽 Table이 Driving된다면, 먼저 sort unique
오퍼레이션을 수행함으로써 1쪽 집합으로 만든 다음에 조인합니다.
2) 메인 Query 쪽 Table이 Driving된다면 Semi Join방식으로 Join을 합니다.
[ Sort Unique 오퍼레이션수행 ]
DEPT Table의 PK 제약을 제거,
DEPTNO 컬럼에 Nonunique Index를 생성 후
실행계획을 확인해보도록 하겠습니다.
[SQL]
ALTER TABLE DEPT DROP PRIMARY KEY;
CREATE INDEX DEPT_DEPTNO_IDX ON DEPT(DEPTNO);
SELECT * FROM EMP
WHERE DEPTNO IN (SELECT DEPTNO FROM DEPT);

실제로 DEPT Table은 Unique한 집합이지만 옵티마이저는 이를 확신할 수 없어
Sort Unique 오퍼레이션을 수행하고
아래처럼 Query 변환이 일어났습니다.
[SQL]
SELECT B.*
FROM ( SELECT /*+ NO_MERGE */ DISTINCT DEPTNO FROM DEPT ORDER BY DEPTNO ) A, EMP B
WHERE B.DEPTNO = A.DEPTNO;
결과가 잘 안나타나는데
Query를 아래처럼 변형한 후 Test
[SQL]
SELECT /*+ LEADING(DEPT@QB1) USE_NL(EMP) */ *
FROM EMP
WHERE DEPTNO IN (SELECT /*+ UNNEST QB_NAME(QB1) */ DEPTNO FROM DEPT);
[ 세미 조인 방식으로 수행 ]
[SQL]
SELECT * FROM EMP
WHERE DEPTNO IN (SELECT DEPTNO FROM DEPT);

NL Semi Join의 수행은
결과집합이 M쪽 집합으로 확장된느 것을 방지하는 알고리즘을 사용
Outer(=Driving) Table의 한 Row가 Inner Table의 한 Row와 Join에 성공하는 순간 진행을 멈추고
Outer Table의 다음 Row를 계속 처리하는 방식

옵티마이저가 NL Semi Join 수행 안할 때는 아래 처럼 Hint를 주어 사용 가능
[SQL]
SELECT /*+ LEADING(EMP) */ * FROM EMP
WHERE DEPTNO IN (SELECT /*+ UNNEST NL_SJ */ DEPTNO FROM DEPT);
07. 필터 오퍼레이션과 세미조인의 캐싱 효과
옵티마이저가 Query 변환을 수행하는 이유는, 더 나은 실행계획을 수립할 가능성을 높이는데 있으며
다양한 조인 방식의 선택과, 조인 순서에 있습니다.
Subquery를 Unnesting 하지 않으면 최적화 하는데 제한적이며 불리합니다.
=> 단순히 메인 쿼리를 수행하면서 건건히 Subquery Block을 매번 수행(Filter Operation)해야 하기 때문
=> 대량의 집합 기준으로 Random Access 방식으로 Subquery 집합을 필터한다면 수행속도 나쁘며
=> 유일한 Filter에 대한 최적화 기법의 한가지는 Subquery 수행 결과를 버리지 않고
내부 Cache에 저장하고 있다 같은 값이 입력되면 저장된 값을 출력
08. Anti 조인
Not Exists, Not In Subquery도 Unnesting 하지 않으면
Filter 방식으로 처리된다.
[SQL]
SELECT * FROM DEPT D
WHERE NOT EXISTS
(SELECT /*+ NO_UNNEST */ 'X' FROM EMP WHERE DEPTNO = D.DEPTNO);
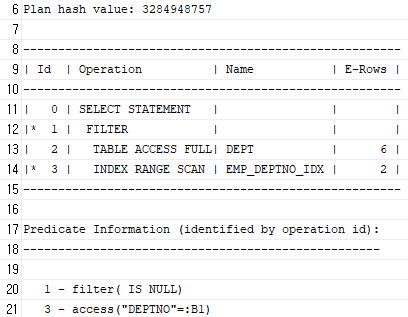
[ EXISTS 필터 ] : Join에 성공하는 (서브) Record를 만나는 순간 결과집합에 담고
다른 (메인) Record로 이동한다.
[ NOT EXISTS 필터 ] : Join에 성공하는 (서브) Record를 만나는 순간 버리고
다음 (메인) Record로 이동한다.
Join에 성공하는 (서브) Record가 하나도 없을 때만 결과집합에 담는다.
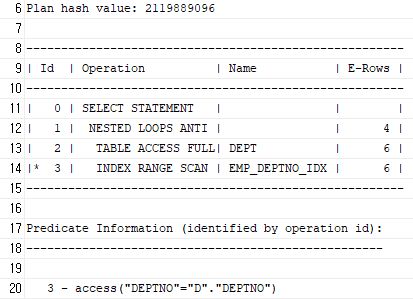
똑같은 Query를 Unnesting 하면 아래와 같이 Anti Join 방식으로 처리
[SQL]
SELECT * FROM DEPT D
WHERE NOT EXISTS
(SELECT /*+ UNNEST NL_AJ */ 'X' FROM EMP WHERE DEPTNO = D.DEPTNO);
[SQL]
SELECT * FROM DEPT D
WHERE NOT EXISTS
(SELECT /*+ UNNEST MERGE_AJ */ 'X' FROM EMP WHERE DEPTNO = D.DEPTNO);

09. 집계 서브쿼리 제거
집계 함수를 포함하는 Subquery를 Unnesting 하고,
이를 다시 분석 함수로 대체하는 Query는 10g에서 도입되었습니다.
[SQL]
SELECT D.DEPTNO, D.DNAME, E.EMPNO, E.ENAME, E.SAL
FROM EMP E, DEPT D
WHERE D.DEPTNO = E.DEPTNO
AND E.SAL >= (SELECT AVG(SAL) FROM EMP WHERE DEPTNO = D.DEPTNO);
위 Query를 Unnesting하면 1차적으로 아래와 같은 Query가 만들어집니다.
[SQL]
SELECT D.DEPTNO, D.DNAME, E.EMPNO, E.ENAME, E.SAL
FROM (SELECT DEPTNO, AVG(SAL) AVG_SAL FROM EMP GROUP BY DEPTNO) X, EMP E, DEPT D
WHERE D.DEPTNO = E.DEPTNO
AND E.DEPTNO = X.DEPTNO
AND E.SAL >= X.AVG_SAL;
옵티마이저는 한 번 더 Query 변환을 시도해 Inline View를 Merging하거나 그대로 둔 채 최적화 할 수 있습니다.
10g부터 옵티마이저가 선택할 수 있는 옵션이 한 가지 더 추가되었는데,
Subquery로부터 전환된 Inline View를 제거하고 아래와 같이 메인 Query에 분석 함수를
사용하는 형태로 변환하는 것입니다.
이 기능은 _REMOVE_AGGR_SUBQUERY 파라미터에 의해 제어되며, 비용기반으로 작동
[SQL]
SELECT DEPTNO, DNAME, EMPNO, ENAME, SAL
FROM (
SELECT D.DEPTNO, D.DNAME, E.EMPNO, E.ENAME, E.SAL
,(CASE WHEN E.SAL >= AVG(SAL) OVER (PARTITION BY D.DEPTNO)
THEN E.ROWID END) MAX_SAL_ROWID
FROM EMP E, DEPT D
WHERE D.DEPTNO = E.DEPTNO
)
WHERE MAX_SAL_ROWID IS NOT NULL;
[ 아래는 집계 Subquery 제거 기능이 작동 ] 했을 때의 실행계획입니다.
Query에선 EMP Table을 두 번 참조했지만 실행계획상으로는 한 번만 Access했고,
대신 Window Buffer Operation 단계가 추가 되었습니다.
[SQL]
SELECT D.DEPTNO, D.DNAME, E.EMPNO, E.ENAME, E.SAL
FROM DEPT D, EMP E
WHERE D.DEPTNO = E.DEPTNO
AND E.SAL = (SELECT MAX(SAL) FROM EMP WHERE DEPTNO = D.DEPTNO);

[ 아래는 집계 Subquery 제거 기능이 작동하지 못하도록 파라미터를 변경했을 때 ]
[SQL]
ALTER SESSION SET "_REMOVE_AGGR_SUBQUERY" = FALSE;
SELECT D.DEPTNO, D.DNAME, E.EMPNO, E.ENAME, E.SAL
FROM DEPT D, EMP E
WHERE D.DEPTNO = E.DEPTNO
AND E.SAL = (SELECT MAX(SAL) FROM EMP WHERE DEPTNO = D.DEPTNO);

10. Pushing 서브쿼리
- Unnesting 되지 않은 Subquery는 항상 Filter 방식으로 처리되며,
대개 실행계획 상에서 맨 마지막 단계에 처리
만약 Subquery Filtering을 먼저 처리했을 때 다음 수행 단계로 넘어가는 Row 수를 크게
줄일 수 있다면 성능은 그만큼 향상된다.
[ Pushing 서브쿼리 ] : 실행계획 상 가능한 앞 단계에서 Subquery Filtering이 처리되도록 강제하는 것
이를 제어하하기 위해 사용하는 옵티마이저 힌트로는
[ PUSH_SUBQ ]
※ Pushing Subquery는 Unnesting 되지 않은 Subquery에만 작동!!
따라서 PUSH_SUBQ 힌트는 NO_UNNEST 힌트와 같이 기술하는 것이 올바른 사용법!!!
Oracle 버전에 따라 Push_subq 힌트 사용 위치가 다르다는 점도 아래를 통해 알 수 있습니다.
[9i에서 Push_subq 힌트 사용시]
SELECT /*+ PUSH_SUBQ LEADING(E1) USE_NL(E2) */ SUM(E1.SAL), SUM(E2.SAL)
FROM EMP1 E1, EMP2 E2
WHERE E1.NO = E2.NO
AND ~~~~~~~~
AND EXISTS (SELECT /*+ NO_UNNEST */ 'X' FROM DEPT
WHERE ~~~~~~~~
AND ~~~~~~~~);
[10g에서 Push_subq 힌트 사용시]
SELECT /*+ LEADING(E1) USE_NL(E2) */ SUM(E1.SAL), SUM(E2.SAL)
FROM EMP1 E1, EMP2 E2
WHERE E1.NO = E2.NO
AND ~~~~~~~~
AND EXISTS (SELECT /*+ NO_UNNEST PUSH_SUBQ */ 'X' FROM DEPT
WHERE ~~~~~~~~
AND ~~~~~~~~);
[Pushing 서브쿼리를 통해 성능 개선 효과가 나타나는지 테스트]
[Script]
CREATE TABLE EMP1 AS
SELECT * FROM EMP, (SELECT ROWNUM NO FROM DUAL CONNECT BY LEVEL <= 1000);
CREATE TABLE EMP2 AS SELECT * FROM EMP1;
ALTER TABLE EMP1 ADD CONSTRAINT EMP1_PK PRIMARY KEY(NO, EMPNO);
ALTER TABLE EMP2 ADD CONSTRAINT EMP2_PK PRIMARY KEY(NO, EMPNO);
[SQL]
SELECT /*+ LEADING(E1) USE_NL(E2) */ SUM(E1.SAL), SUM(E2.SAL)
FROM EMP1 E1, EMP2 E2
WHERE E1.NO = E2.NO
AND E1.EMPNO = E1.EMPNO
AND EXISTS (SELECT /*+ NO_UNNEST NO_PUSH_SUBQ */ 'X'
FROM DEPT WHERE DEPTNO = E1.DEPTNO
AND LOC = 'NEW YORK');
아래는 EMP1과 EMP2 Table을 Join하고 나서 Subquery Filtering을 수행할 때의 트레이스 결과

EMP2 Table과의 Join 시도 횟수가 14,000번이었지만 여기서는
Subquery를 Filtering한 결과 건수가 3,000건이므로 EMP2 Table과의 Join 횟수도 3,000번으로 줄었습니다.
읽은 Block 수도 28,103개에서 6,103개로 줄었다.
[SQL]
SELECT /*+ LEADING(E1) USE_NL(E2) */ SUM(E1.SAL), SUM(E2.SAL)
FROM EMP1 E1, EMP2 E2
WHERE E1.NO = E2.NO
AND E1.EMPNO = E1.EMPNO
AND EXISTS (SELECT /*+ NO_UNNEST PUSH_SUBQ */ 'X'
FROM DEPT WHERE DEPTNO = E1.DEPTNO
AND LOC = 'NEW YORK');
아래는 EMP1과 EMP2 Table을 Join하고 나서 Subquery Filtering을 수행할 때의 트레이스 결과

※ Pushing Subquery는 Unnesting 되지 않은 Subquery의 처리 순서를 제어하는 기능
'오라클 성능고도화 2권' 카테고리의 다른 글
| Chap04. 01 쿼리 변환이란? (0) | 2021.08.12 |
|---|---|
| Chap02. 07 조인을 내포한 DML 튜닝 (0) | 2021.08.10 |
| Chap02. 06 스칼라 서브쿼리를 이용한 조인 (0) | 2021.08.09 |
| Chap02. 05 Outer 조인 (0) | 2021.08.08 |
| Chap02. 04 조인 순서의 중요성 (0) | 2021.08.08 |


