- 인덱스 구조
- 인덱스란?
- 인덱스의 기본 구조
- Root -> Branch -> Leaf
- 인덱스탐색
- 수직적탐색 + 수평적탐색
- 인덱스 기본 원리
- Index 사용이 불가능하거나 범위 스캔이 불가능한 경우
- 인덱스 컬럼의 좌변가공
- Null의 검색
- 묵시적 형변환
- 부정형 일 때
- 위와 같은 상황이 발생안하도록 Query를 작서아는 방법
- SQL 튜닝
- 함수기반인덱스 활용
- Index 사용이 불가능하거나 범위 스캔이 불가능한 경우
- 다양한 인덱스 스캔 방식
- 인덱스 스캔 방식
- Index Range Scan
- Index Full Scan
- Index Unique Scan
- Index Skip Scan
- Index Fast Full Scan
- Index Range Scan Decending
- Index Combine
- Inlist Iterator
- 인덱스 스캔 방식
- Table Random Access 부하
04. 테이블 Random Access 부하
1) 인덱스 Rowid에 의한 Table Access란?
Index Leaf에서 하나의 Rowid를 읽어 Hash Function을 통해 나온 값들을 Bucket으로
역은 부분과 Memory 에서 Block의 Row의 Rowid에 Hash Function을 통해 값을
Bucket의 값을 비교하면서 발생하는 Latch들과 읽는 것 하나가 이만큼 내부적으로 일을 많이한다.
Disk에서 읽을 땐 더 부하 심하다.
Cache Buffer Chain Latch -> Hash Bucket List들 사이의 Chain
Buffer Busy Wait -> db_buffer_cache에서 해당 Block이 사용 중인지
=> Rowid가 Table Record와 물리적으로 연결이 안되어있기 때문
Buffer Pinning - Logical Read Count로 잡히지 않음
다음 번 Read 시 현재 읽은 동일 Block을 Read 할 경우 대상 Block이
Age-Out되지 않도록 Pin을 걸어두고, 해당 주소인 DBA가 가리키는 메모리 번지수를
PGA에 저장하여 바로 찾아가는 기법
Buffer의 3종류
* Free Buffer
* Pinned Buffer
* Dirty Buffer
2) 인덱스 클러스터링 팩터(Clustering Factor)
군집성 계수
Data가 얼마큼 Index 구조로 모여있는가?
- Index를 순차적으로 읽어 이전 Rowid Block과 다음 Rowid Block이 상이할 때 1 증가

3) 인덱스 손익분기점
언제 Index를 이용한 Table Random Access 보다 Table Full Scan이 좋으냐?
Index RowId에 의한 Table Random Access -> Random Access
Table Full Scan -> Sequential Access
Disk I/O 시 Index RowId에 의한 Table Random Access -> Single Block Read
-- Table Full Scan -> Multiblock Read
손익분기점 극복 위한 기능
- IOT(Index-Organized Table)
Table을 Index 구조로 생성
- Clustered Table
키 값이 같은 Record는 같은 Block에 모이도록 저장
- Partition Table
05. 테이블 Random Access 최소화 튜닝
1) 기존 인덱스 컬럼 추가
2) PK 인덱스에 컬럼 추가
3) 인덱스 컬럼 추가에 따른 클러스터링 팩터 변화
4) 인덱스만 읽고 처리
5) 버퍼 Pinning 효과 활용
6) 수동으로 클러스터링 팩터 높이기
06. IOT, 클러스터 테이블 활용
1) IOT(Index-Organized Table)
Index 구조로 Table 생성
ms-sql에서는 Clustered Index라 부른다.
[생성문]
CREATE TABLE INDEX_ORG_T (A NUMBER PRIMARY KEY, B VARCHAR(10))
ORGANIZATION INDEX;
[장점]
* 같은 값을 가진 Record들이 100% 정렬되있기에
-> Random Access가 아닌 Sequential 방식으로 Data를 Access한다
* PK Index를 위한 별도의 Segment를 생성안하기에 공간 절약
[단점]
* Data 입력 시 성능이 느리다
* Index Split에 의한 성능 저하 크다.
* Direct Path Insert가 작동 X
2) IOT, 언제 사용할 것인가?
* 크기가 작고 NL 조인으로 반복 룩업하는 테이블
* 폭이 좁고 긴 테이블
* 넓은 범위를 주로 검색하는 테이블
* 데이터 입력과 조회 패턴이 서로 다른 테이블
3) Partitioned IOT
(IOT + Partitionning)
4) Overflow 영역
주요 컬럼과 사용안하는 컬럼을 구분하여
서로다른 저장영역에 저장하여 분리하는 방법
CREATE TABLE T (
PK 관련 속성
.....
시스템 관리 속성 컬럼들
)
ORGANIZATION INDEX
OVERFLOW TABLESPACE TBS_OVRFL01 -- OVERFLOW SEGMENT가 저장될 Tablespace 명
PCTTHRESHOLD 30 -- 블록 크기의 30%를 초과하기 직전 컬럼까지만 Index 블록에 저장
나머지는 OVERFLOW영역에 저장
INCLUDING 적출건수; -- Including에 지정한 컬럼까지만 Index Block에 저장
나머지는 Overflow 영역 저장
5) Secondary 인덱스
- 생성할거라면 IOT로 안만드는 것이 좋다.
6) 인덱스 클러스터 테이블
클러스터 키 값이 같은 레코드가 물리적으로 한블록에 모이도록 저장
(IOT와 다른점)

하나의 키에 여러개의 데이터를 가지고 있다.
07. 인덱스 스캔 효율
- Sequential Access의 선택도를 높인다
- Random Access 발생량을 줄인다.
1) 비교 연산자 종류와 컬럼 순서에 따른 인덱스 레코드의 군집성
최대한 등치조건인 컬럼을 Index 구성의 앞쪽으로 빼도록하자
그래야 Data가 모여있는 정도가 좁아진다.
2) 인덱스 선행 컬럼이 등치(=) 조건이 아닐 때 발생하는 비효율
3) Between 조건을 IN-List로 바꾸었을 때 인덱스 스캔 효율
가끔 Between 조건을 In으로 변경할 경우 효과 볼때있음
* In-list 개수 적어야함(In절 수만큼 수직적탐색 발생)
* 수직적탐색 비용 > 수평적탐색 비용
* Index Depth가 높을 때 비용 ↑
4) Index Skip Scan을 이용한 비효율 해소
Index Skip Scan의 Branch만 재방문하여
다시 Leaf Block을 재탐색을 할 때 이점인 경우 있다.(BETWEEN, LIKE)

판매구분 = 'A' 인 경우
5) 범위검색 조건을 남용할 때 발생하는 비효율
특정컬럼 값 들어올수 있다 없다.
=> 개발자 Like로 해결 => 성능저하 => Index 구조때문
ⓐ 특정컬럼 not null 컬럼일때
WHERE 특정컬럼 = NVL(:인자, 특정컬럼)
ⓑ 특정컬럼 null 컬럼일때
SQL1
WHERE :인자 IS NULL
.....
UNION ALL
SQL2
WHERE :인자 IS NOT NULL
AND 특정컬럼 = :인자
6) 같은 컬럼에 두 개의 범위검색 조건 사용 시 주의 사항
WHERE COL1 <= 10000
AND COL2 <= 10;
범위를 따져 좌변가공을 통해 Index를 못타도록 만든다.
WHERE Trim(COL1) <= 10000
AND COL2 <= 10;
7) Between과 Like 스캔 범위 비교
- Between을 사용하는 것이 정확한 방식이나, 개발자들의 편리에 의해 Like 사용
- Between을 사용하면 성능적으로 손해볼 것이 없다.

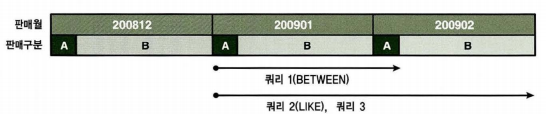
8) 선분이력의 인덱스 스캔 효율
최근 데이터를 주로 읽을 때 : 인덱스 : [ 종료일자 + 시작일자 ]
과거 데이터를 주로 읽을 때 : 인덱스 : [ 시작일자 + 종료일자 ]
인덱스 수정 불가한 상황 : Index_Desc Hint
중간지점을 읽을 때 어떤 인덱스든 비효율 발생 Rownum <= 1활용
※ Index Skew
인덱스 엔트리가 왼쪽 도는 오른쪽으로 치우치는 현상
대량의 데이터를 지우는 작업을 마치고 난 후

한쪽이 빈 현상
- 빈 블록은 Free-List로 등록되지만 반환하지 않음
- 재사용 가능하나, 다시 채워 질 때까지 인덱스 스캔 효율 저하
※ Index Sparse
인덱스 블록 전반에 걸쳐 밀도가 떨어지는 현상

- 대량의 삭제 작업 후 발생
- 인덱스 밀도 낮은 현상
- Skew 처럼 완전히 빈 블록은 재 사용되지만
- 완전 빈 블록은 거의 없기에 데이터가 채워질 때까지 인덱스 비효율 발생
※ Index Rebuild 요건
- 인덱스 분할에 의한 경합이 현저히 높을 때
- 자주 사용되는 인덱스 스캔 효율을 높이고자 할 때, 특히 NL Join에서 반복
액세스되는 인덱스 높이가 증가했을 때
- 대량의 DELETE 작업을 수행한 이후 다시 레코드가 입력되기까지 오랜 기간이 소요될 때
- 총 레코드 수가 일정한데도 인덱스가 계속 커질 때
08. 인덱스 설계
09. 비트맵 인덱스

- DW환경에서 주로 사용 OLTP환경에서는 DML 부하 생김
- Distinct Value개수가 적을 때
- 적은 용량을 차지하므로 인덱스가 여러개 필요한 대용량 테이블에 유용
- 다양한 분석관점을 가진 팩트성 테이블에 주로 사용
※ 단독으로 쓰임이 없는 단일 인덱스가
여러 비트맵 인덱스를 동시 활용 시 대용량 데이터 검색 성능 향상에 효과
'오라클 성능고도화 2권' 카테고리의 다른 글
| Chap01. 05 테이블 Random 액세스 최소화 튜닝 (0) | 2021.07.27 |
|---|---|
| Chap01. 04 테이블 Random 액세스 부하 (0) | 2021.07.21 |
| Chap01. 03 다양한 인덱스 스캔 방식 (0) | 2021.07.16 |
| Chap01. 02 인덱스 기본 원리 (0) | 2021.07.14 |
| Chap01. 01 인덱스 구조 (0) | 2021.07.13 |



